

Across industries, artificial intelligence (AI) is optimizing workflows, increasing efficiency, driving innovation—and driving investment in accelerators, deep learning processors, and neural processing units (NPUs). Some organizations start in small groups with search augmented generation (RAG) for inference tasks before gradually expanding to accommodate more users. Enterprises that process large volumes of private data may prefer to set up their own training clusters to achieve the accuracy that custom models built on selected data can provide. Whether you’re investing in a small AI cluster with hundreds of accelerators or a massive setup with thousands, you’ll need a scalable network to connect them all.
key? Proper planning and design of this network. A well-designed network ensures that your accelerators achieve peak performance, complete tasks faster, and keep end-to-end latency to a minimum. In order to speed up the completion of the task, the network must prevent congestion or at least catch it in time. The network also needs to handle traffic smoothly, even during in-cast scenarios – in other words, it should manage congestion immediately as it occurs.
This is where the Data Center Quantized Congestion Notification (DCQCN) comes in. The DCQCN concept works optimally when Explicit Congestion Notification (ECN) and Priority Flow Control (PFC) are used in combination. ECN responds in a timely manner on a per-flow basis, while PFC serves as a hard measure to mitigate congestion and prevent packet drops. Our data center network design for AI/ML applications explains these concepts in detail. We’ve also introduced Nexus Dashboard AI fabric templates to facilitate deployment according to plan and best practices. In this blog, we’ll explain how the Cisco Nexus 9000 Series switches use a dynamic load balancing approach to deal with congestion.
Traditional and dynamic approaches to load balancing
Traditional load balancing uses equal-cost multipath (ECMP), a routing strategy where once a flow chooses a path, it often persists for the duration of that flow. When multiple flows stick to the same persistent path, it can result in some links being overused while others are underutilized, resulting in congestion of overused links. In an AI training cluster, this can increase job completion time and even lead to higher latency, which can compromise the performance of training jobs.
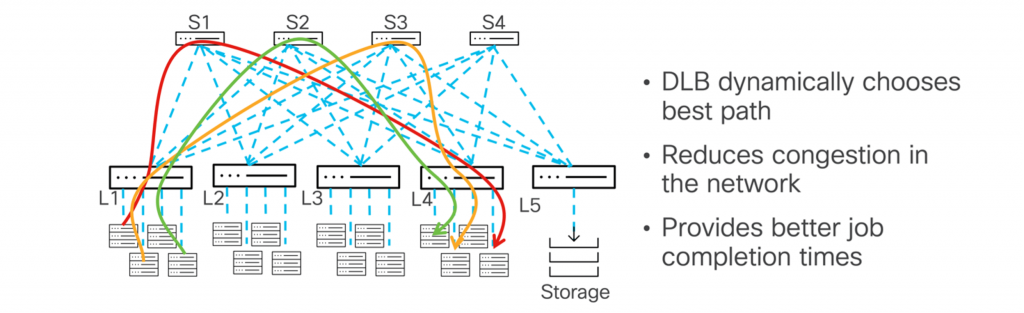
Since the state of the network is constantly changing, load balancing must be dynamic and driven by real-time feedback from network telemetry or user configurations. Dynamic Load Balancing (DLB) enables more efficient and dynamic traffic distribution in response to changes in the network. As a result, congestion can be avoided and overall performance can be improved. By continuously monitoring the state of the network, it can adjust the path for flow – switching to less-used paths if congestion occurs.
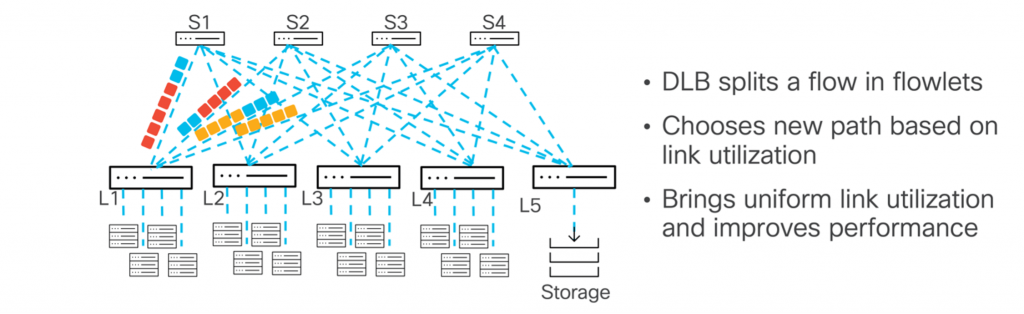
The Nexus 9000 series uses link utilization as a parameter when deciding how to use multipath. Since link utilization is dynamic, realigning flows based on path utilization enables more efficient forwarding and reduces congestion. When comparing ECMP and DLB, note this key difference: With ECMP, once a quintuple flow is assigned to a particular path, it stays on that path even if the link becomes congested or heavily used. DLB, on the other hand, starts by placing five times the flow on the least used link. If this link becomes more heavily used, DLB will dynamically move the next set of packets (known as a flow) to another, less congested link.
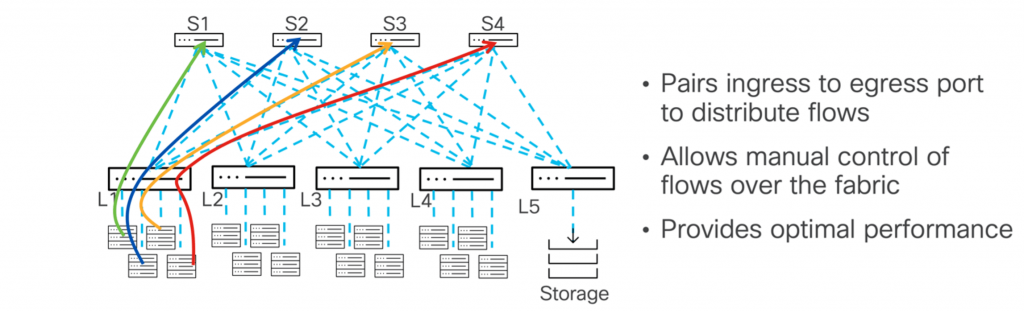
For those who like to be in control, the Nexus 9000 Series DLB lets you fine-tune the load balancing between input and output ports. By manually configuring the pairing between input and output ports, you can gain more flexibility and accuracy in traffic control. This allows you to control the load on the output ports and reduce congestion. This approach can be implemented through a command-line interface (CLI) or application programming interface (API), facilitating large-scale networks and allowing manual traffic distribution.
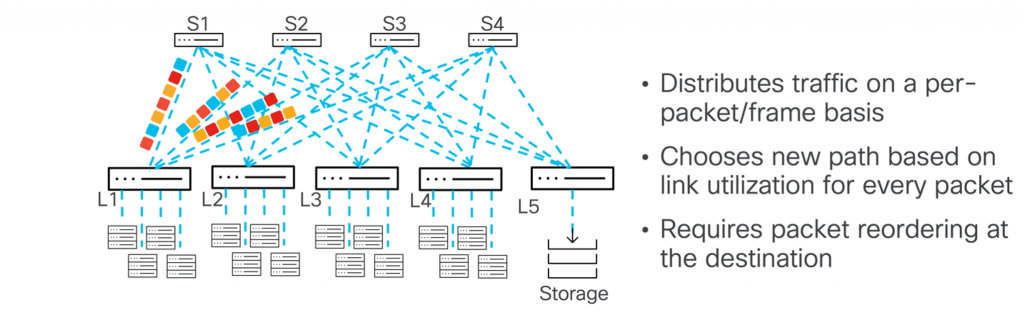
The Nexus 9000 series can spray packets across the fabric using packet-based load balancing, sending each packet along a different path to optimize traffic flow. This should ensure optimal connection utilization as packets are distributed randomly. However, it is important to note that packets can arrive at the destination host out of order. The host must be able to reorder packets or process them as they arrive and maintain the correct processing in memory.
Performance improvement on the go
Looking to the future, new standards will further improve performance. Members of the Ultra Ethernet consortium, including Cisco, have worked to develop standards spanning many layers of the ISO/OSI stack to improve AI and high-performance computing (HPC) workloads. Here’s what that could mean for the Nexus 9000 series switches and what to expect.

Scalable transport, better control
We focused on creating standards for a more scalable, flexible, secure and integrated transport solution – Ultra Ethernet Transport (UET). The UET protocol defines the new transmission method as connectionless, which means that it does not require a “handshake” (a term used to create a preliminary connection setup process between communication devices). Transmission begins when a connection is established; the connection is then dropped after the transport is complete. This approach allows for better scalability and reduced latency, and can even reduce network card (NIC) costs.
Congestion control is built into the UET protocol and directs NICs to distribute traffic across all available paths in the fabric. Optionally, the UET can use lightweight telemetry (round-trip time delay measurement) to collect information about network path usage and congestion and deliver this data to the receiver. Packet trimming is another optional feature that helps detect congestion early. It works by only sending header information for packets that will be dropped due to a full buffer. This gives the receiver a clear method to inform the sender of congestion, helping to reduce retransmission delays.
UET is an end-to-end transmission where endpoints (or NICs) share the transmission equally with the network. Connectionless transmission begins and ends with the sender and receiver. The network requires two classes of traffic for this transmission: one for data traffic and one for control traffic, which is used to acknowledge receipt of data traffic. For data traffic, Explicit Congestion Notification (ECN) is used to signal congestion on the route. Data traffic can also be transmitted over a lossless network, allowing for flexible transmission.
Prepared for UET admission and more
The Nexus 9000 Series switches are UEC ready, making it easy to quickly and seamlessly adopt the new UET protocol with your existing and new infrastructure. All mandatory features are supported today. Nice optional features like packet clipping are supported in Cisco Silicon One-based Nexus products. Nexus 9000 series switches will support additional features in the future.
Build your network for maximum reliability, precise control, and peak performance with the Nexus 9000 Series. Get started today by enabling dynamic load balancing for AI workloads. Once UEC standards are ratified, we’ll be ready to help you upgrade to Ultra Ethernet NICs, unlock the full potential of Ultra Ethernet, and optimize your fabric to future-proof your infrastructure. Are you ready to optimize your future? Start building it with the Nexus 9000 Series.
Share: